屁大点事写个帖子
pycharm 格式化 Ctrl+Shift+L,
每次写完(改完)顺手格式化一下,
非常的舒服。
最近开始接触开源项目,
很多用的 black 格式化工具,
还有 mypy 等等代码检查工具。
冲突点在于 pycharm 另起的一行的参数空 8 格,
black 空四格。
在用 black 风格检查的代码的情况下,
pycharm 的格式化显得不友好了。
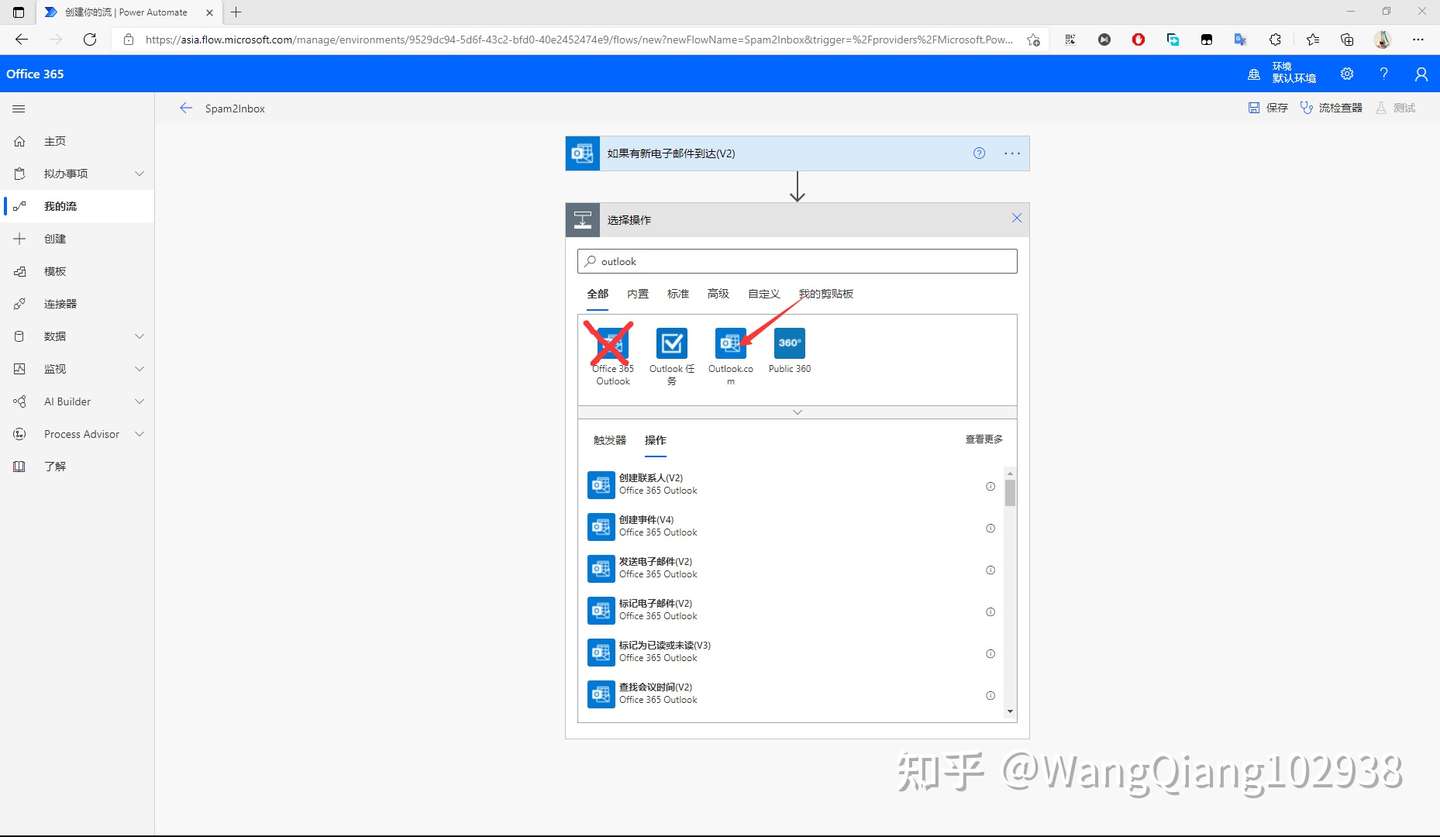
最开始想直接 pycharm reformat 用上 black,但是看了看 jetbrain 的插件:
BlackConnect 要起服务端,而且快捷键不同 (Alt + Shift + B)
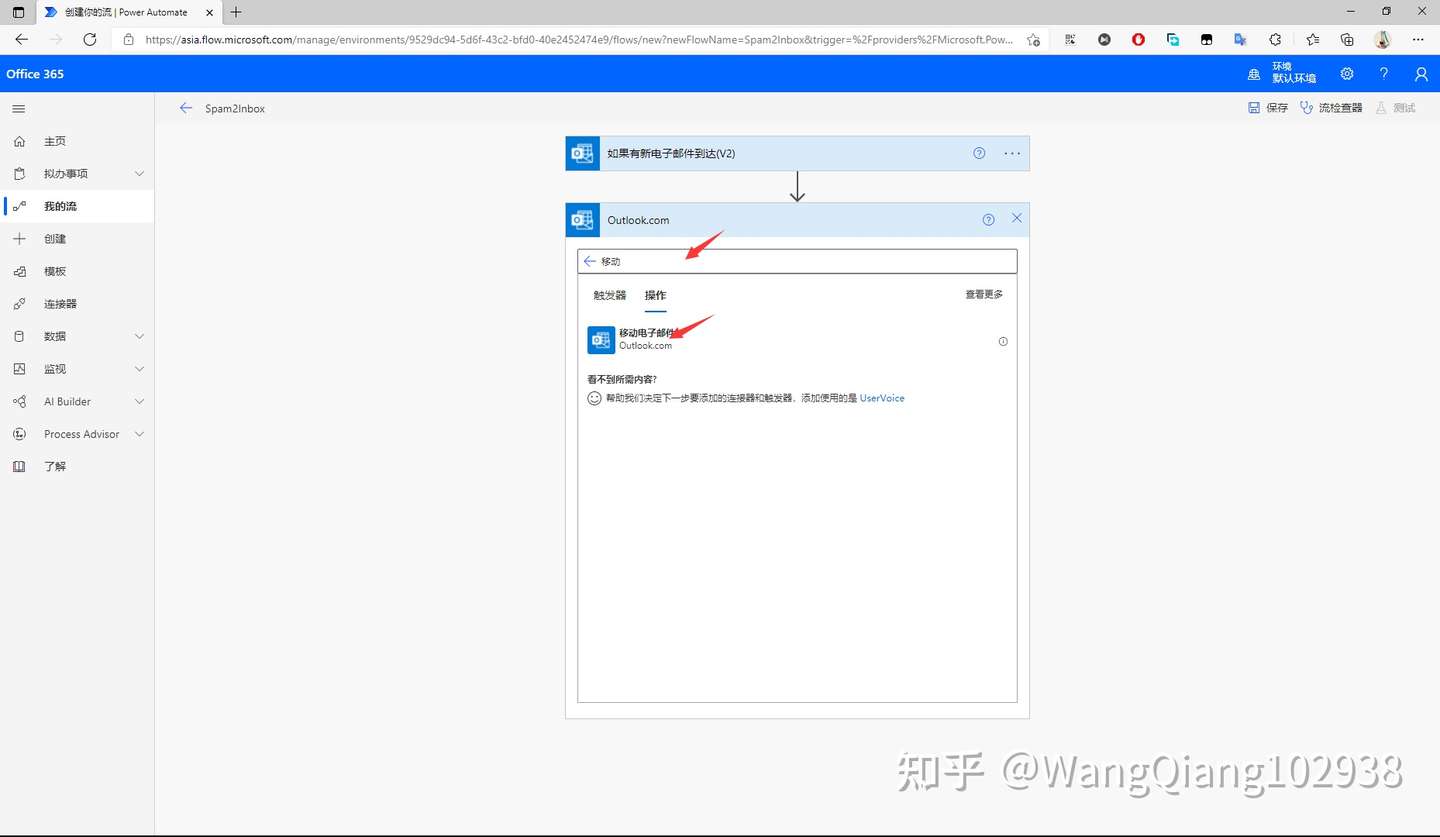
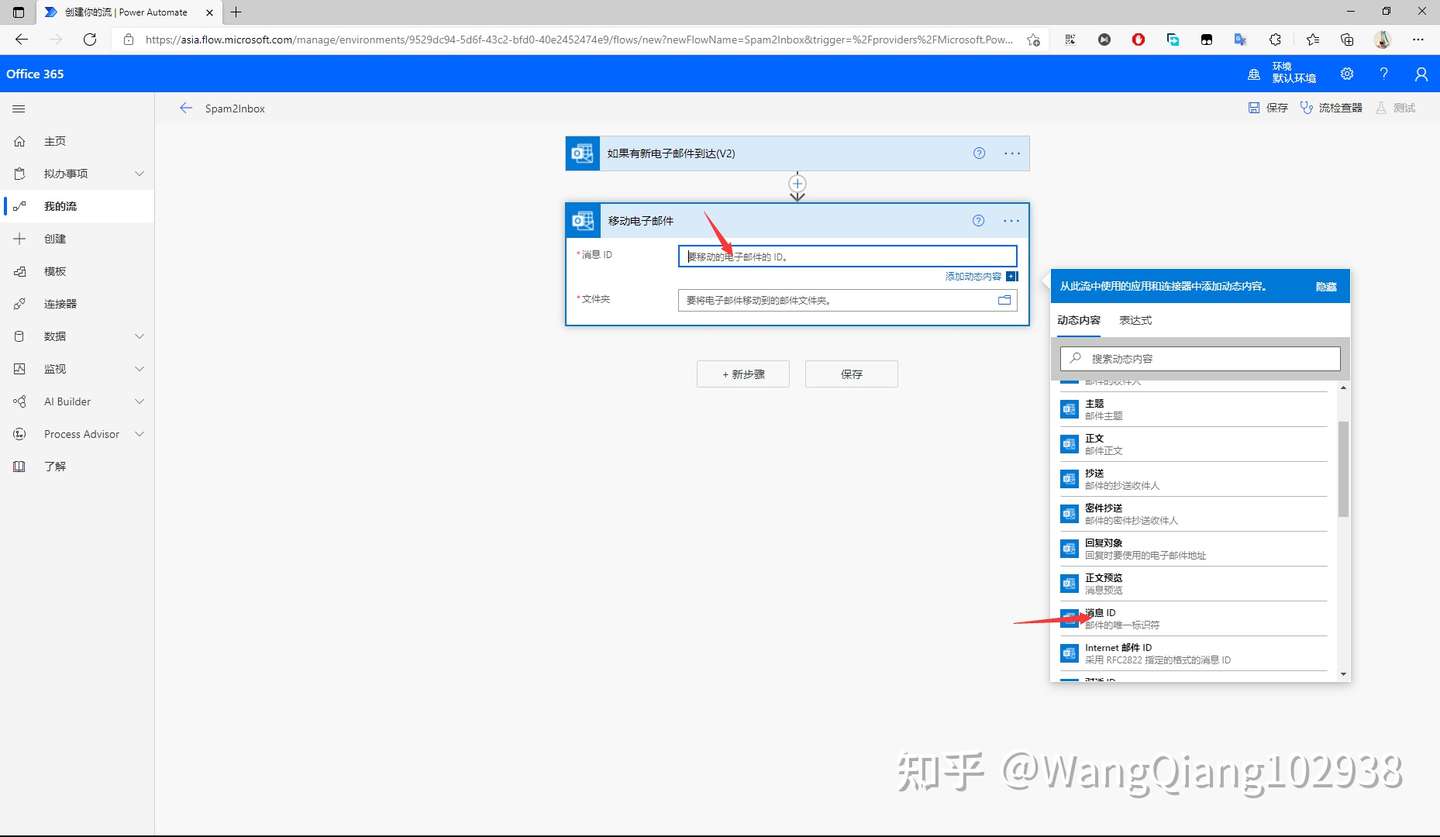
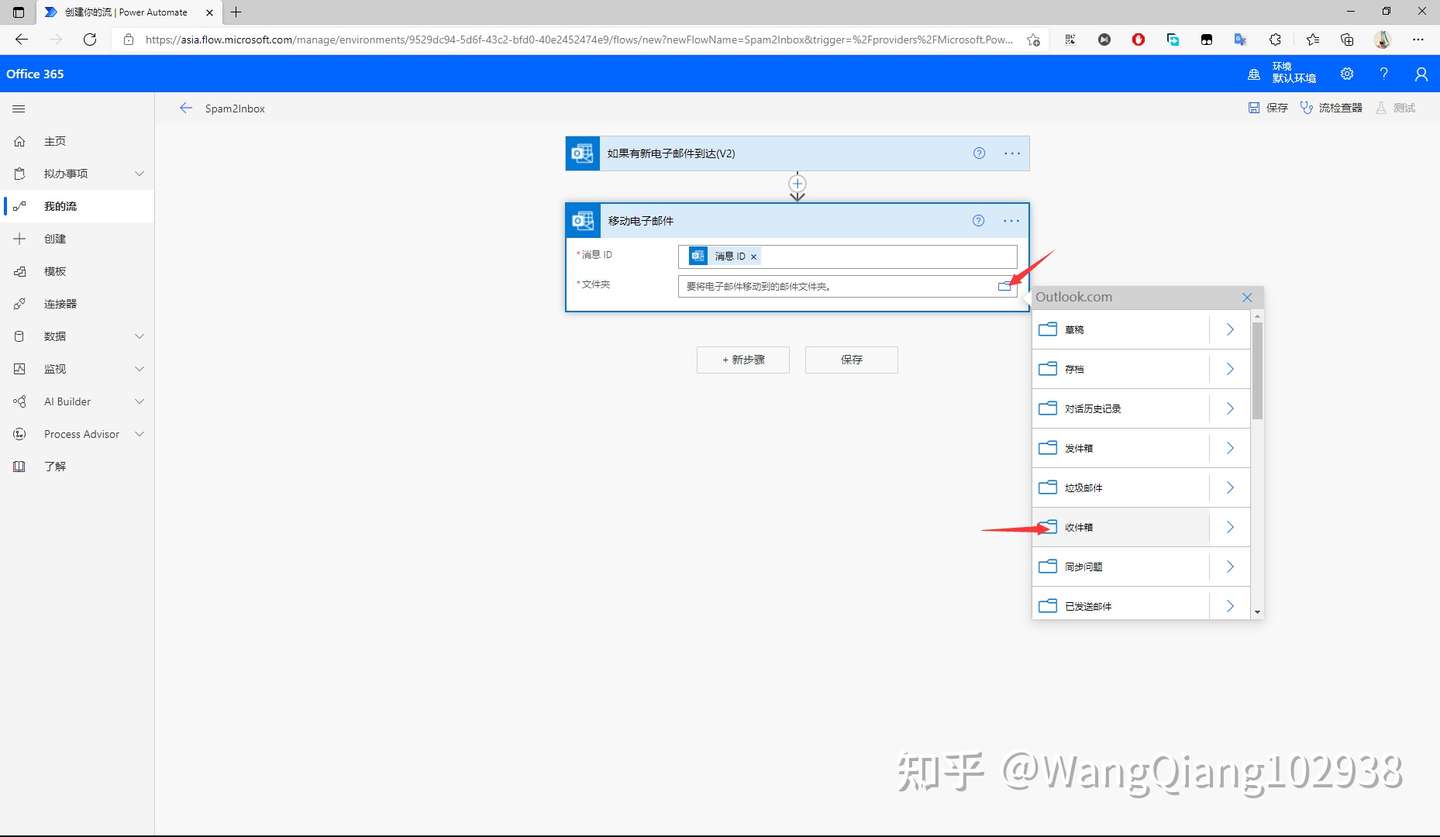
后面还是妥协普通编写时用 pycharm reformat
提交时统一 black 格式化
需要的是把Continuation indent 改为4

后期再通过 git hook 格式化或者检查代码
windows 下 先 python 安装 black isort
pip install black isort -U
pip install black==22.1 isort==5.10 -U # 安装指定版本
然后找到 black 和 isort 的命令位置
File -> Settings -> Tools -> External Tools
按+号按钮 增加新的拓展工具
Name: Black
Description: Black is the uncompromising Python code formatter.
Program: <install_location_from_step_2>
# Program: d:/ProgramData/Miniconda3/Scripts/black.exe
Arguments: $FilePath$
Name: Isort
Description: Sort imports in current file
Program: <install_location_from_step_2>
# Program: d:/ProgramData/Miniconda3/Scripts/black.exe
Arguments: -e -m 4 -w 120 $FilePath$
Settings -> Keymap -> External Tools -> External Tools
- Black. 选择后输入
Ctrl+Alt+L 顶掉原来的快捷键
- Isort. 同理,输入
Ctrl+Alt+O 顶掉原有的 import 格式化
pycharm 原有设置 (方便小伙伴还原)
| 拓展工具 | 原有快捷键名称 | 快捷键 |
|---|
| Black | Reformat Code | Ctrl+Alt+L |
| Isort | Optimize Imports | Ctrl+Alt+O |
��参考一下 fastapi
mypy fastapi
flake8 fastapi tests
black fastapi tests --check
isort fastapi tests docs_src scripts --check-only
或者用 python 插件 pre-commit-hooks
配��置参考这个项目 simple_calculate_service
- repo: https://github.com/pre-commit/pre-commit-hooks
sha: v1.11.1
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-json
- id: flake8
exclude: migrations|.*\_local.py|manage.py|settings.py
参考 fastapi-crudrouter
lint:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
- name: Run Black Code Formatter
uses: psf/black@stable
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r tests/dev.requirements.txt
- name: Check Typing with mypy
run: |
mypy fastapi_crudrouter
- name: Lint with flake8
run: |
flake8 fastapi_crudrouter

报错:The Black Formatter server crashed 5 times in the last 3 minutes. The server will not be restarted. See the output for more
修改配置 其他不用改:
{
"black-formatter.path": [
"C:\\Users\\z7407\\AppData\\Roaming\\Python\\Python310\\Scripts\\black.exe"
]
}
快捷键配置 看是否能搜索到
命令窗 搜索 Format Document with... 设置 black 为 Default