import itertools
import numpy
import pandas
from rqalpha.apis import *
__config__ = {
"base": {
"start_date": "20190101",
"end_date": "20191231",
'frequency': '1d',
"accounts": {
"stock": 50000,
},
"data_bundle_path": r"E:\data\bundle",
},
"extra": {
"log_level": "debug",
},
"mod": {
"sys_progress": {
"enabled": True,
"show": True
}, "sys_accounts": {
"enabled": True,
"dividend_reinvestment": True,
},
"sys_analyser": {
"enabled": True,
"plot": True,
'benchmark': '000300.XSHG',
},
},
}
def init(context):
context.mean_coe = 0.8
context.mean_days = 244
context.rise_days = context.config.extra.rise_days
context.fall_days = context.config.extra.fall_days
context.rise_x = context.config.extra.rise_x
context.fall_x = context.config.extra.fall_x
context.order_ticker = [
"002111.XSHE",
"002673.XSHE",
"601375.XSHG",
]
df = all_instruments('CS')
df = df[df.listed_date.apply(lambda x: x.year in [2015, 2016, 2017])]
context.order_ticker = context.order_ticker + df.order_book_id.to_list()
def before_trading(context):
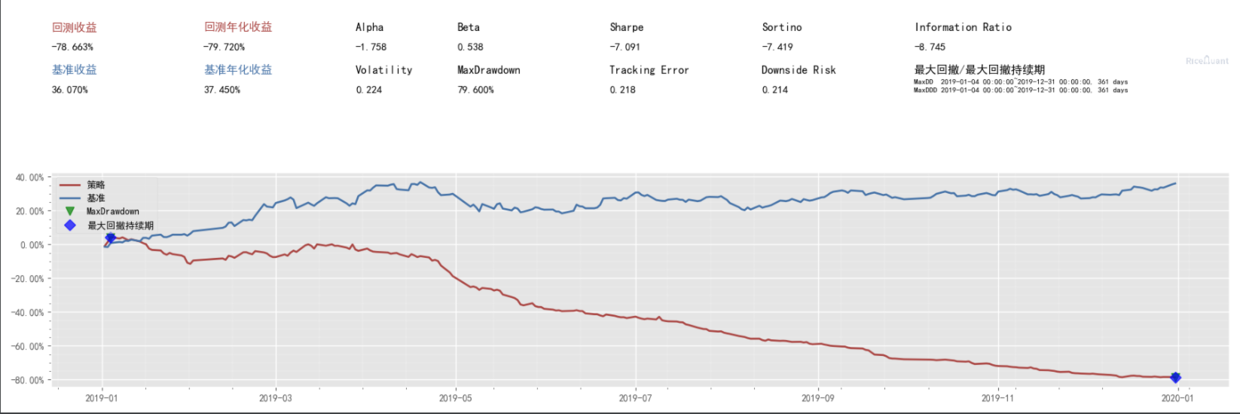
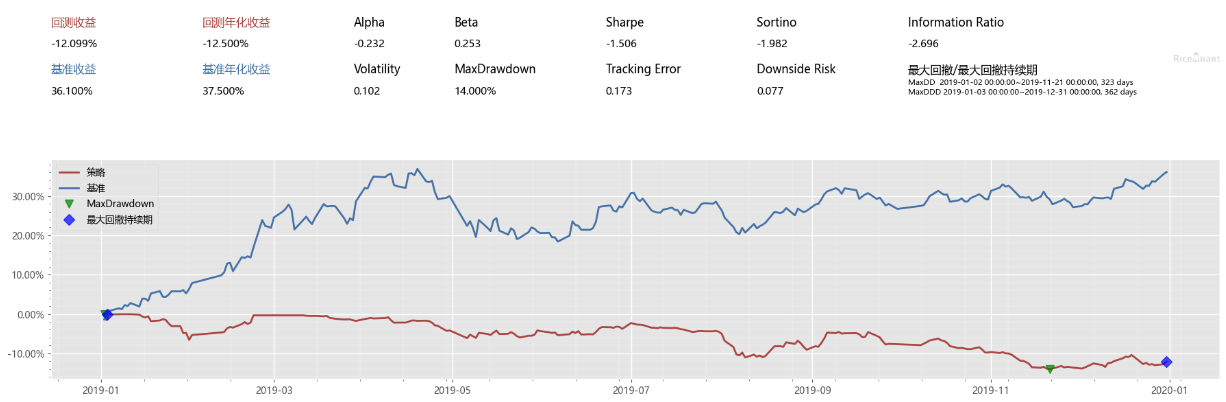
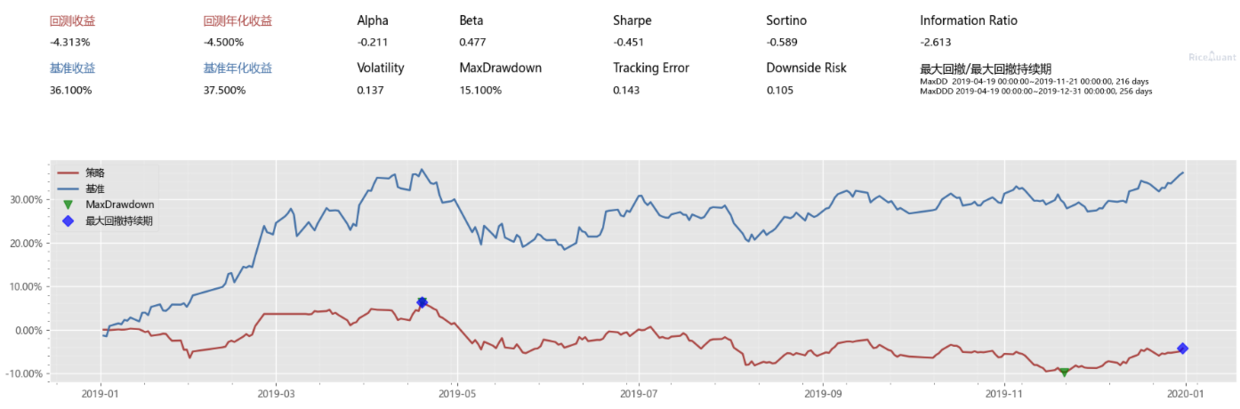
print("年化:{}".format(context.portfolio.total_returns))
context.mean_close = {}
for order_book_id in context.order_ticker:
bars = pandas.Series([i[0] for i in history_bars(order_book_id, context.mean_days, "1d", fields=['close'])])
context.mean_close[order_book_id] = bars.mean()
def handle_bar(context, bar_dict):
if context.stock_account.cash >= 5000:
for order_book_id in context.order_ticker:
bar_close = bar_dict[order_book_id].close
if bar_close < (context.mean_close[order_book_id] * context.mean_coe):
_str = ""
bars = pandas.Series(
[i[0] for i in history_bars(order_book_id, context.fall_days, "1d", fields=['close'])])
_str += "\n" + f"[{order_book_id}] 价格 ({bar_close}) 低于一年平均价{context.mean_close[order_book_id]}"
if not (bars.shift(-1, fill_value=0) < bars).all():
continue
_str += "\n" + f"[{order_book_id}] 连跌 价格表现为{list(bars)}"
if not (bars[0] * context.fall_x > bar_close):
continue
_str += "\n" + f"[{order_book_id}] 跌幅超过{context.fall_x}, {bars[0]} - {bar_close}"
o = order_value(order_book_id, 5000)
if o:
_str += "\n" + f"[{order_book_id}] 买入".format(order_book_id)
print(_str)
for order_book_id in context.order_ticker:
position = context.portfolio.positions[order_book_id]
bar_close = bar_dict[order_book_id].close
if position is None or position.quantity <= 0:
continue
if position.avg_price < bar_close:
continue
_str = ""
bars = pandas.Series([i[0] for i in history_bars(order_book_id, context.fall_days, "1d", fields=['close'])])
if not (bars.shift(1, fill_value=0) < bars).all():
continue
_str += "\n" + f"[{order_book_id}] 连涨 价格表现为{list(bars)}"
if not (bars[0] * context.rise_x < bar_close):
continue
_str += "\n" + f"[{order_book_id}] 涨幅超过{context.rise_x}, {bars[0]} - {bar_close}"
o = order_target_percent(order_book_id, 0)
if o:
_str += "\n" + f"[{order_book_id}] 出售".format(order_book_id)
print(_str)
def after_trading(context):
pass
import rqalpha
rise_days = range(3, 10)
fall_days = range(3, 10)
rise_x = numpy.arange(1.06, 1.12, 0.01)
fall_x = numpy.arange(0.9, 0.94, 0.01)
config_map = itertools.product(rise_days, fall_days, rise_x, fall_x)
df = pandas.DataFrame(config_map, columns=["rise_days", "fall_days", "rise_x", "fall_x", ])
result_list = []
for _, item in df.iterrows():
__config__['extra']['rise_days'] = int(item.rise_days)
__config__['extra']['fall_days'] = int(item.fall_days)
__config__['extra']['rise_x'] = item.rise_x
__config__['extra']['fall_x'] = item.fall_x
result = rqalpha.run_func(init=init,
before_trading=before_trading,
handle_bar=handle_bar,
after_trading=after_trading,
config=__config__)
total_returns = result['sys_analyser']['summary']['total_value']
result_list.append(result)