-
项目用到了 socket io 通信 发送信息
-
client 和 server 直连无问题
-
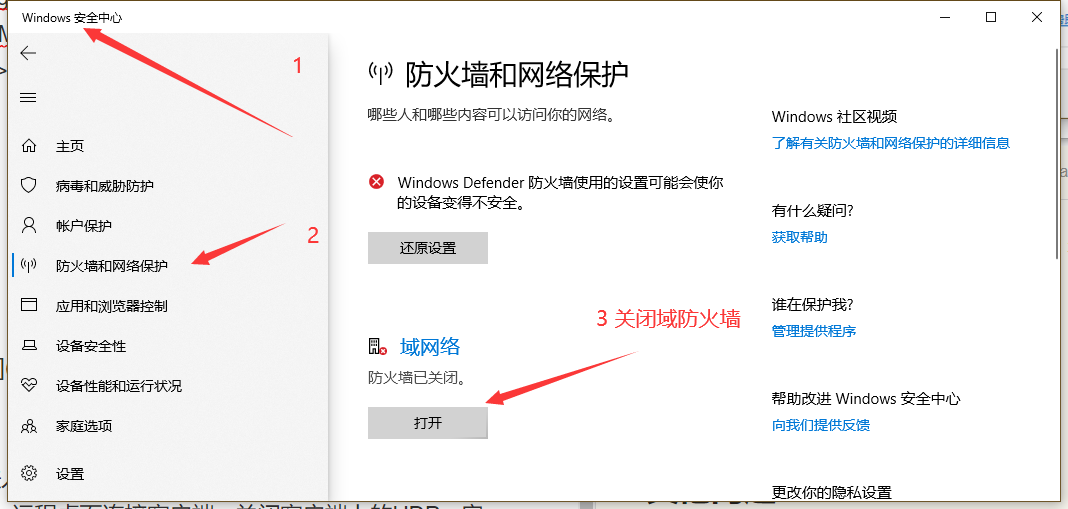
但是走 niginx 集群就直接报错了
-
大神改了一个配置然后就通过了
-
记录一下 Nginx 配置

location /socket.io {
proxy_pass http://pro_socketio;
proxy_http_version 1.1;
proxy_set_header upgrade $http_upgrade;
proxy_set_header connection $connection_upgrade;
proxy_set_header x-real-ip $remote_addr;
proxy_set_header x-forwarded-for $proxy_add_x_forwarded_for;
proxy_set_header host $http_host;
proxy_set_header x-nginx-proxy true;
proxy_set_header Access-Control-Allow-Origin *; # 主要起作用
proxy_set_header Origin ""; # 主要起作用字段
proxy_read_timeout 86400;
}