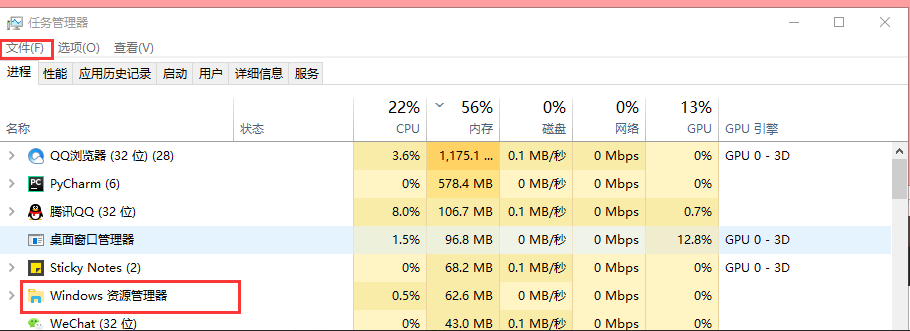
-----> [2018-07-16 17:22:42,041] [ERROR] [base.py<131>-base.run_job]: Job "auto_rollback.<locals>.wrapper (trigger: interval[0:30:00], next run at: 2018-07-16 17:52:42 CST)" raised an exception
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/sqlalchemy/engine/base.py", line 1193, in _execute_context
context)
File "/usr/local/lib/python3.6/site-packages/sqlalchemy/engine/default.py", line 507, in do_execute
cursor.execute(statement, parameters)
File "/usr/local/lib/python3.6/site-packages/MySQLdb/cursors.py", line 250, in execute
self.errorhandler(self, exc, value)
File "/usr/local/lib/python3.6/site-packages/MySQLdb/connections.py", line 50, in defaulterrorhandler
raise errorvalue
File "/usr/local/lib/python3.6/site-packages/MySQLdb/cursors.py", line 247, in execute
res = self._query(query)
File "/usr/local/lib/python3.6/site-packages/MySQLdb/cursors.py", line 411, in _query
rowcount = self._do_query(q)
File "/usr/local/lib/python3.6/site-packages/MySQLdb/cursors.py", line 374, in _do_query
db.query(q)
File "/usr/local/lib/python3.6/site-packages/MySQLdb/connections.py", line 277, in query
_mysql.connection.query(self, query)
_mysql_exceptions.OperationalError: (2006, 'MySQL server has gone away')
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/apscheduler/executors/base.py", line 125, in run_job
retval = job.func(*job.args, **job.kwargs)
File "/home/zza/eth_crawler/crawler_script/utils.py", line 28, in wrapper
raise err
File "/home/zza/eth_crawler/crawler_script/utils.py", line 24, in wrapper
return func(*args, **kwargs)
File "/home/zza/eth_crawler/crawler_script/token_tracker.py", line 240, in update
db_address = db.session.query(Token.contract_address).filter(None == Token.total_supply).all()
File "/usr/local/lib/python3.6/site-packages/sqlalchemy/orm/query.py", line 2773, in all
return list(self)
File "/usr/local/lib/python3.6/site-packages/sqlalchemy/orm/query.py", line 2925, in __iter__
return self._execute_and_instances(context)
File "/usr/local/lib/python3.6/site-packages/sqlalchemy/orm/query.py", line 2948, in _execute_and_instances
result = conn.execute(querycontext.statement, self._params)
File "/usr/local/lib/python3.6/site-packages/sqlalchemy/engine/base.py", line 948, in execute
return meth(self, multiparams, params)
File "/usr/local/lib/python3.6/site-packages/sqlalchemy/sql/elements.py", line 269, in _execute_on_connection
return connection._execute_clauseelement(self, multiparams, params)
File "/usr/local/lib/python3.6/site-packages/sqlalchemy/engine/base.py", line 1060, in _execute_clauseelement
compiled_sql, distilled_params
File "/usr/local/lib/python3.6/site-packages/sqlalchemy/engine/base.py", line 1200, in _execute_context
context)
File "/usr/local/lib/python3.6/site-packages/sqlalchemy/engine/base.py", line 1413, in _handle_dbapi_exception
exc_info
File "/usr/local/lib/python3.6/site-packages/sqlalchemy/util/compat.py", line 203, in raise_from_cause
reraise(type(exception), exception, tb=exc_tb, cause=cause)
File "/usr/local/lib/python3.6/site-packages/sqlalchemy/util/compat.py", line 186, in reraise
raise value.with_traceback(tb)
File "/usr/local/lib/python3.6/site-packages/sqlalchemy/engine/base.py", line 1193, in _execute_context
context)
File "/usr/local/lib/python3.6/site-packages/sqlalchemy/engine/default.py", line 507, in do_execute
cursor.execute(statement, parameters)
File "/usr/local/lib/python3.6/site-packages/MySQLdb/cursors.py", line 250, in execute
self.errorhandler(self, exc, value)
File "/usr/local/lib/python3.6/site-packages/MySQLdb/connections.py", line 50, in defaulterrorhandler
raise errorvalue
File "/usr/local/lib/python3.6/site-packages/MySQLdb/cursors.py", line 247, in execute
res = self._query(query)
File "/usr/local/lib/python3.6/site-packages/MySQLdb/cursors.py", line 411, in _query
rowcount = self._do_query(q)
File "/usr/local/lib/python3.6/site-packages/MySQLdb/cursors.py", line 374, in _do_query
db.query(q)
File "/usr/local/lib/python3.6/site-packages/MySQLdb/connections.py", line 277, in query
_mysql.connection.query(self, query)
sqlalchemy.exc.OperationalError: (_mysql_exceptions.OperationalError) (2006, 'MySQL server has gone away') [SQL: 'SELECT token.contract_address AS token_contract_address \nFROM token \nWHERE token.total_supply IS NULL'] (Background on this error at: http://sqlalche.me/e/e3q8)