转 盘点 Python 中的那些冷知识
Python阅读需 1 分钟
代码人生:编织技术与生活的博客之旅

在有幸体会过 996 的生活,早上 8.30 上班,中午休息两个小时,下午 6 点吃晚饭,晚饭后 7.30 上班到 9 点。
说是到九点,其实到了十点十一点还在公司,到宿舍洗漱后,差不多十二点了。
人是有硬性的娱乐时间(人必须有一定的自我放松时间,如果工作对自己来说不轻松的话,忘了那个地方说的了。),人是社会性动物,必须保证至少 4 个小时的社交 (《人类简史》)。996 的工作强度下,人的精神就很容易出问题。
再一个就是,在 996 的工作环境下,就只有周日了,周日是需要补觉的,那么一上午就没了,下午在看看生活必需品,那么连见朋友的时间都没了。
之前看过 广为人知 (che di feng sha) 的大项目 996.ICU,在国内环境确实感受到了严重的 内卷 和员工压榨。
确实也有很多讲述自身经验的方法,比如在 ICU 项目下:
因为家庭因素,我确实可以考虑出国发展,首选加拿大,加拿大最近有个 三年移民计划,对应的 加拿大 IT 人员计划 也有。发出来供大家参考。

加拿大,首先,考虑付费移民(如果有钱的话,五十万左右。去加拿大创业开店),相关信息,推荐搜索抖音号 [北美理李察德 (TopTalk)],非 IT 行业的方式都有,印象比较深的是去读加拿大的南翔技校,读个会计啥出来直接就业,逃离国内内卷环境。
IT 行业,我去加拿大的招聘网站看了看:
首先公司是支持完全远程上班的,对应的工资 19k-34k (参考 知乎,可能我搜索方式不对),然后英语其实要求很高。
对我而言,首要考虑把英语过了,雅思没到 7 分,其实大部分做不了。

为啥说大部分做不了呢,因为还有一条路,在中国找一家外企,比如 ThoughtWorks(思特沃克),做半年到一年后申请外调,到国外后,适应环境后在考虑把工作签证换成绿卡。
这种模式还有好处,在国内享受国外的制度,没有加班,年假长,福利好,被开除有很多很多的补偿。
简单搜索了一下,领英是最好的方式。参考 。其次是 glassdoor。
如果几种方式都不行,那么我想到的比较好的方式是,首先在国内支持远程上班的公司工作,然后在通过雅思去国外,这样在接触新环境的时候,不会因为脱产而产生过多的困难。
首先,远程上班的劣势要列一下(来自朋友分享):
与常规招聘渠道不太一样,这里有一下渠道共大家选择:

在疫情下,远程办公和远程面试得到了最大限度的发展。国内外很多公司已经完全支持远程办公,比如 Facebook,有点是 IT 终于摆脱地理限制,对国内而言,慢慢房价不再是一个问题,低成本同时意味着更大的竞争和更低的成本,国内首先考虑同样 10k 的价格,为何不雇一个已经会老家的 n 年经验的老员工,而在深圳雇佣一个 10k 的实习生,更大一点是,10k 的价格可以在印度雇佣三个程序猿。..
再这么一个内卷时代,先跳出来的人,就是第一个占位子的人。
换个地方呆确实是个考虑的方式,但是同时要考虑亲人朋友的感受,也同时要考虑会不会是从这座城进入了另一座城。
当然国家一定会有地方保护的法律�出来,比如 微软允许员工永久在家办公。
Jeff 大佬的观点,如果内卷是个必然趋势,那么看大一点,要内卷就卷全球。其实也是另外一个角度的黑暗森林。

先考虑其他收入渠道也是个很好的方式。为了防止这方面更内卷,我就不多说了。



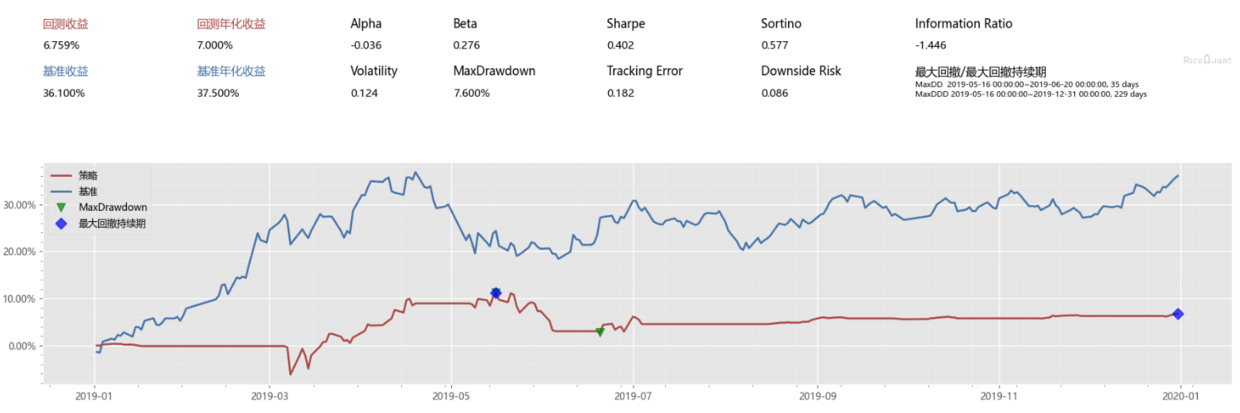
2019 年 01 -- 2020 年 01,回测收益,表示的是我本金到时间结束,涨了多少,比如我有 5w,那么这个图表示我年末结束涨到了 5*(0.09+1) = 5.45(万元)。基准收益, 这个我一般设置的是沪深三百,也就是大盘,这个图表示 19 年大盘涨了30+%,而我的策略只有9+%,其实是没有跑赢大盘的 (还不如买基金)。好了,下面开始正文。
这个是一个普遍的购买思路,觉得底价股票一定会长,我短期持有然后等他高于某个价格就出售,我模拟一下这个情况,下面是代码:
#!/usr/bin/python3
# encoding: utf-8
# @Time : 2020/11/18 14:32
# @author : zza
# @Email : 740713651@qq.com
import warnings
import pandas
import rqdatac
__config__ = {
"base": {
"start_date": "20190101",
"end_date": "20191231",
'frequency': '1d',
"accounts": {
"stock": 5000,
}
},
"mod": {
"sys_progress": {
"enabled": True,
"show": True
}, "sys_accounts": {
"enabled": True,
"dividend_reinvestment": True,
},
"sys_analyser": {
"enabled": True,
"plot": True,
'benchmark': '000300.XSHG',
},
}
}
def init(context):
context.lowest = 5
context.highest = 5.9
context.day_count = 0
context.holding_days = 10
def get_ticker(context):
all_ins = rqdatac.all_instruments("Stock").order_book_id.to_list()
price_df = rqdatac.get_price(all_ins, context.now, context.now, expect_df=True, fields=['close'])
price_df = price_df.reset_index(drop=False)
price_df = price_df[(context.lowest <= price_df.close) & (price_df.close <= context.highest)]
start_date = rqdatac.get_previous_trading_date(context.now, 2)
price_df_2 = rqdatac.get_price(price_df.order_book_id.to_list(), start_date, context.now, expect_df=True,
fields=['close']).reset_index(drop=False)
order_ticker = []
for order_book_id, data_df in price_df_2.groupby(price_df_2.order_book_id):
if (data_df.close.shift(fill_value=0) < data_df.close).all():
order_ticker.append(order_book_id)
return order_ticker
def before_trading(context):
context.day_count += 1
if (context.day_count - 1) % context.holding_days == 0:
context.order_ticker = get_ticker(context)
def handle_bar(context, bar_dict):
if (context.day_count - 1) % context.holding_days == 0:
with warnings.catch_warnings():
for item in context.order_ticker:
o = order_target_value(item, 1000)
if o:
print(o)
if (context.day_count - 1) % context.holding_days == (context.holding_days-1):
for item in context.portfolio.positions.keys():
order_target_value(item, 0)
def after_trading(context):
print("total_value {}".format(context.portfolio.total_value))
if (context.day_count - 1) % 15 == 0:
items = []
for k, v in context.portfolio.positions.items():
items.append({"order_book_id": k, "quantity": v.quantity})
print(pandas.DataFrame(items))
if __name__ == '__main__':
import rqalpha
rqalpha.run_func(init=init,
before_trading=before_trading,
handle_bar=handle_bar,
after_trading=after_trading,
config=__config__)
持有 3 个交易日
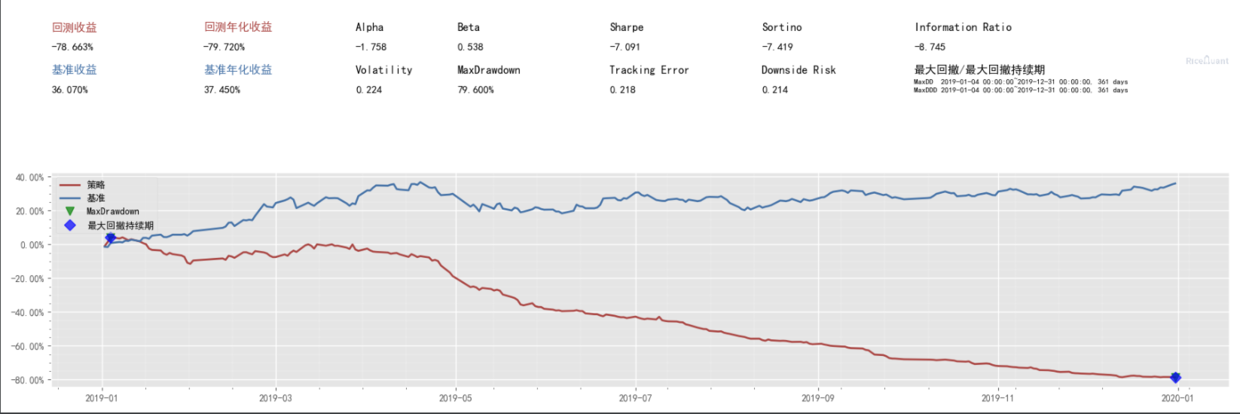
持有 10 个交易日
持有 15 个交易日

结论:底价股票确实会随着大盘的涨而有一定的波动,但最终都是会赔钱的,且三个交易的日的时候,直接赔钱了。这个图可以给广大读者的保佑侥幸心里的朋友看看,一年忙到头,不如买国运(沪深三百)。
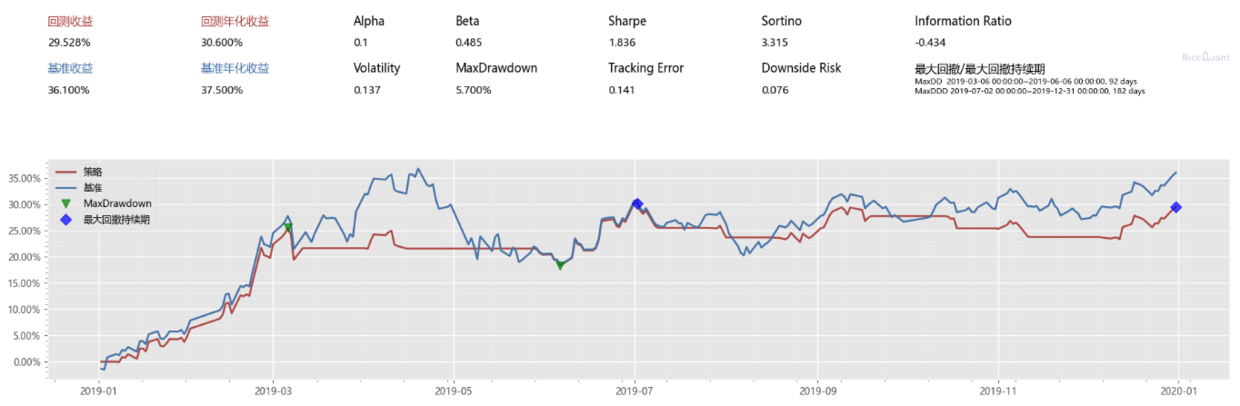
这个是根据我一个朋友跑的算法跑出来的可能会涨的概率。笔者拿到了他一年的数据(没用爬虫),然后试试能不能涨,这么跑的原因是,我当初确实想按着他的这个公众号来买,不过既然有回放数据测试,我当然先测试一下,本金本来就不多,挥霍不了,不敢随便教学费。
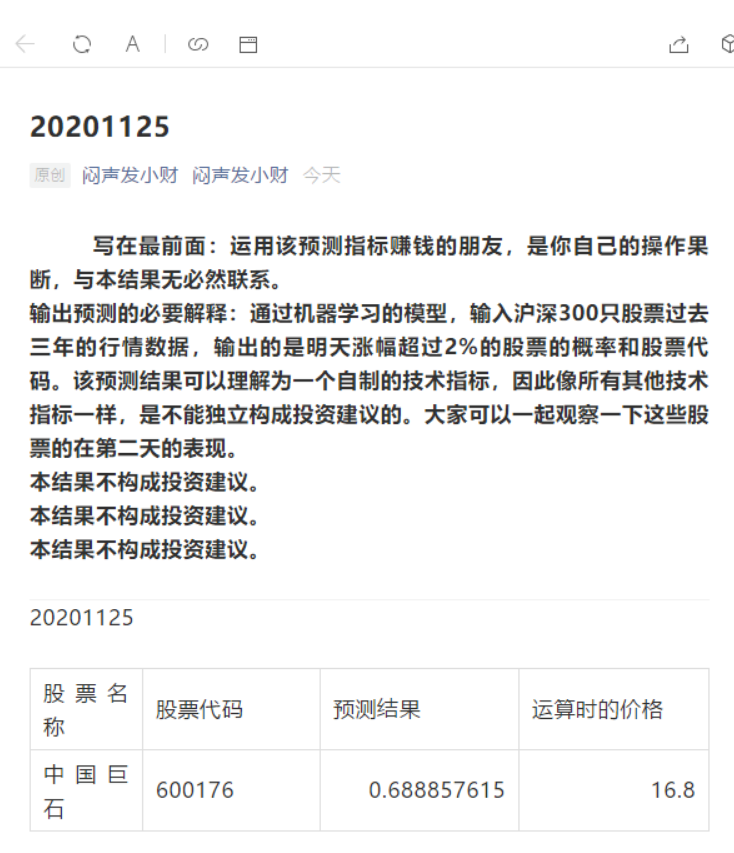
策略如下:
#!/usr/bin/python3
# encoding: utf-8
# @Time : 2020/11/22 16:33
# @author : zza
# @Email : 740713651@qq.com
# @File : 闷声发小财。py
import warnings
import numpy
import pandas
import rqdatac
from rqalpha.apis import *
__config__ = {
"base": {
"start_date": "20190101",
"end_date": "20191231",
'frequency': '1d',
"accounts": {
"stock": 5000,
},
"data_bundle_path": r"E:\data\bundle",
},
"extra": {
"log_level": "debug",
},
"mod": {
"sys_progress": {
"enabled": True,
"show": True
}, "sys_accounts": {
"enabled": True,
"dividend_reinvestment": True,
},
"sys_analyser": {
"enabled": True,
"plot": True,
'benchmark': '000300.XSHG',
},
},
}
def init(context):
context.df = pandas.read_csv("发小财。csv", dtype={"股票代码": numpy.str})
context.df['order_book_id'] = rqdatac.id_convert(context.df["股票代码"].to_list())
context.used_df = context.df[context.df["预测结果"] > 0.7]
context.sell_multiple = 1.08
context.holding_days = 1
context.buy_queen = []
context.sell_map = {}
def before_trading(context):
print("当日购买:{}".format(context.buy_queen))
print("当日持仓:{}".format(list(context.sell_map.keys())))
def handle_bar(context, bar_dict):
while context.buy_queen:
order_book_id = context.buy_queen.pop()
if context.stock_account.cash > 1000:
o = order_value(order_book_id, 1000)
if o:
trading_dt = get_next_trading_date(context.now, context.holding_days).to_pydatetime()
context.sell_map[order_book_id] = trading_dt
print("[{}] 购买成功".format(order_book_id))
else:
print("[{}] 资金不足,无法购买".format(order_book_id))
for order_id, dt in context.sell_map.copy().items():
a = dt.date() <= context.now.date()
b = bar_dict[order_id].close > get_position(order_id).avg_price # * context.sell_multiple
if a and b:
o = order_percent(order_id, -1)
if o:
del context.sell_map[order_id]
print("[{}] 卖出成功".format(order_id))
def dt_to_int(dt):
return dt.year * 10000 + dt.month * 100 + dt.day
def after_trading(context):
df = context.used_df[dt_to_int(context.now) == context.used_df.trading_dt]
if df.empty:
return
else:
for _, item in df.iterrows():
context.buy_queen.append(item["order_book_id"])
if __name__ == '__main__':
import rqalpha
rqalpha.run_func(init=init,
before_trading=before_trading,
handle_bar=handle_bar,
after_trading=after_trading,
config=__config__)
持有一天就卖出
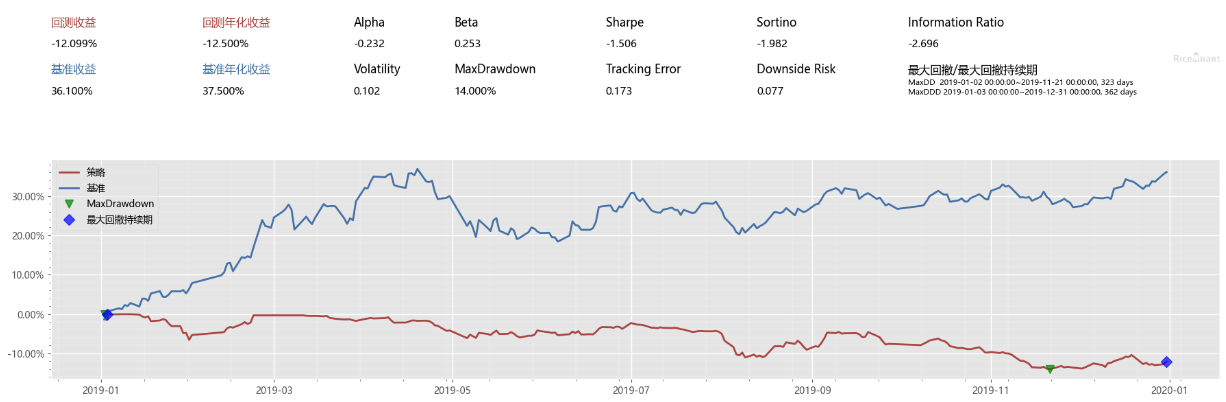
持有 3 天并价格高于持仓价则卖出
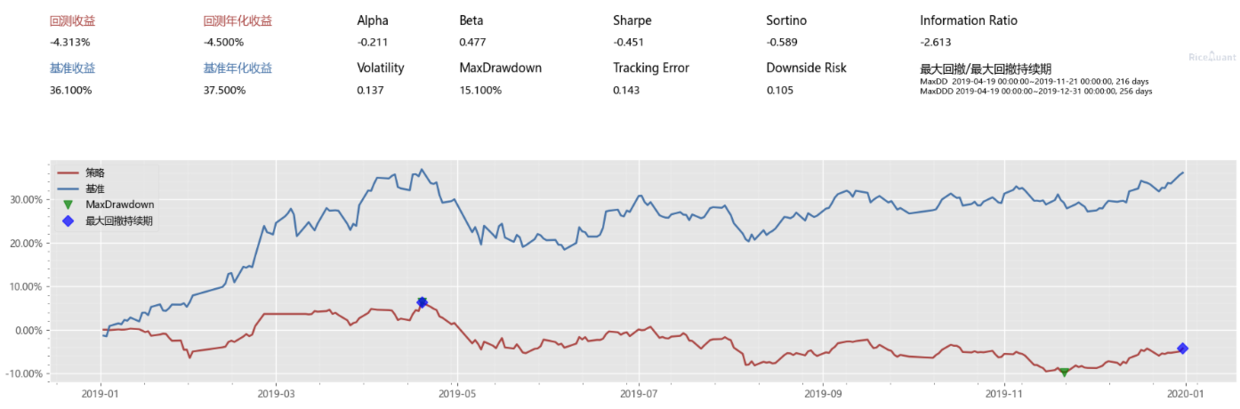
结论:还好跑了回放测试,不然得教好多学费。
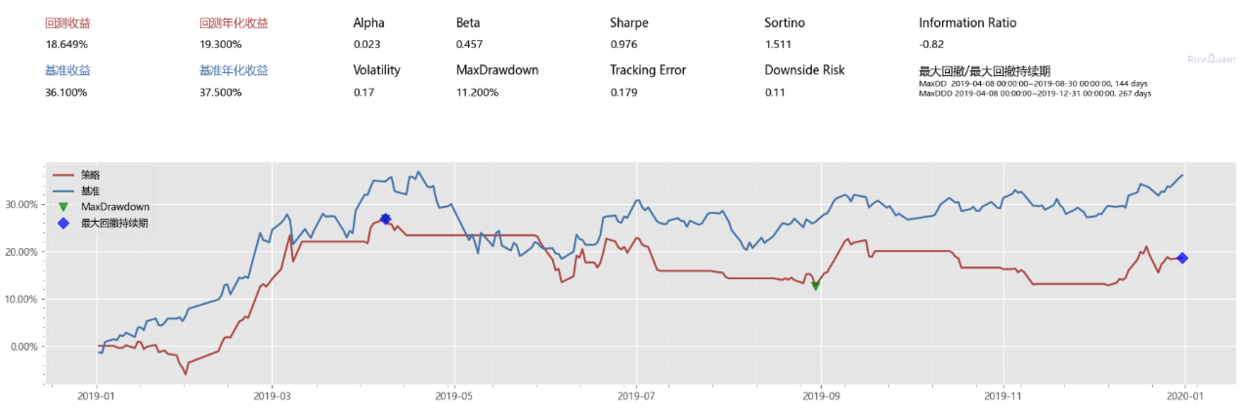
这个也是我在上班的时候偶尔能想到的,我觉得可能也代表一分部分人的想法,**某个行业市场涨幅的时候,必定是全行业性质的,且会持续一段时间。**于是我就写了这个,根据股票行业暴露度(属于哪个行业),分类行业,如果都涨了,就买进,如果都跌了,就卖出。
代码如下:
#!/usr/bin/python3
# encoding: utf-8
# @Time : 2020/11/22 16:33
# @author : zza
# @Email : 740713651@qq.com
# @File : 闷声发小财。py
from collections import defaultdict
from pprint import pprint
import numpy
import pandas
from rqalpha.apis import *
__config__ = {
"base": {
"start_date": "20190101",
"end_date": "20191231",
'frequency': '1d',
"accounts": {
"stock": 50000,
},
"data_bundle_path": r"E:\data\bundle",
},
"extra": {
"log_level": "debug",
},
"mod": {
"sys_progress": {
"enabled": True,
"show": True
}, "sys_accounts": {
"enabled": True,
"dividend_reinvestment": True,
},
"sys_analyser": {
"enabled": True,
"plot": True,
'benchmark': '000300.XSHG',
},
},
}
def get_holding_ticker():
# 请去米筐购买或申请试用 RQData : www.ricequant.com
rqdatac.init()
df = rqdatac.get_factor_exposure(rqdatac.all_instruments("Stock").order_book_id, "20190101", "20191231")
df.reset_index().sort_values("date").to_csv("factor_exposure.csv", index=False)
def init(context):
df = pandas.read_csv("factor_exposure.csv")
all_order_book_id = all_instruments().order_book_id.to_list()
context.df = df[df["order_book_id"].isin(all_order_book_id)]
context.buy_map = defaultdict(list)
context.holding_map = defaultdict(list)
context.sell_factors = []
context.day_count = 0
context.sell_multiple = 1.2
def before_trading(context):
pprint("当日购买行业:{}".format(context.buy_map))
print("当日持仓:{}".format([i.order_book_id for i in get_positions()]))
print("年化:{}".format(context.portfolio.total_returns))
def handle_bar(context, bar_dict):
# buy
for factors, order_book_ids in context.buy_map.items():
if context.stock_account.cash < 2000:
break
for order_book_id in order_book_ids.copy():
o = order_value(order_book_id, 2000)
if o:
context.holding_map[factors].append(order_book_id)
order_book_ids.remove(order_book_id)
# sell
for factors in context.sell_factors:
for order_book_id in context.holding_map[factors].copy():
# a = bar_dict[order_book_id].close > get_position(order_book_id).avg_price * context.sell_multiple
a = True
if a:
o = order_percent(order_book_id, -1)
if o:
context.holding_map[factors].remove(order_book_id)
def dt_to_str(dt):
return "{}-{}-{}".format(dt.year, dt.month, dt.day)
def is_rise(order_book_id):
a, b = history_bars(order_book_id, 2, frequency="1d", fields='close')
return b > a
def after_trading(context):
context.day_count += 1
if context.day_count % 5 != 1:
return
df = context.df[context.now.date().isoformat() == context.df.date].copy()
df.loc[:, 'rose'] = df["order_book_id"].apply(is_rise)
df.loc[:, 'close'] = df["order_book_id"].apply(lambda x: history_bars(x, 1, frequency="1d", fields='close'))
context.sell_factors = []
context.buy_map = defaultdict(list)
for factors in df.columns[13:-2]:
_df = df[df[factors] == 1]
if _df['rose'].sum() / _df['order_book_id'].size > 0.9:
context.buy_map[factors] = _df[(_df["close"] > 5) & (_df["close"] < 6)].sort_values('close')[
'order_book_id'].to_list()[:2]
elif _df['rose'].sum() / _df['order_book_id'].size < 0.3:
context.sell_factors.append(factors)
del df
if __name__ == '__main__':
import rqalpha
rqalpha.run_func(init=init,
before_trading=before_trading,
handle_bar=handle_bar,
after_trading=after_trading,
config=__config__)
emmm,不说了,都是磊。
from collections import defaultdict
from pprint import pprint
import numpy
import pandas
from rqalpha.apis import *
__config__ = {
"base": {
"start_date": "20190101",
"end_date": "20191231",
'frequency': '1d',
"accounts": {
"stock": 50000,
},
"data_bundle_path": r"E:\data\bundle",
},
"extra": {
"log_level": "debug",
},
"mod": {
"sys_progress": {
"enabled": True,
"show": True
}, "sys_accounts": {
"enabled": True,
"dividend_reinvestment": True,
},
"sys_analyser": {
"enabled": True,
"plot": True,
'benchmark': '000300.XSHG',
},
},
}
import talib
def init(context):
context.s1 = '000300.XSHG'
context.SHORTPERIOD = 12
context.LONGPERIOD = 26
context.SMOOTHPERIOD = 9
context.OBSERVATION = 100
subscribe(context.s1)
def before_trading(context):
pass
def handle_bar(context, bar_dict):
closes = history_bars(context.s1, context.OBSERVATION, '1d', 'close')
diff, signal, _ = talib.MACD(closes)
if diff[-1] > signal[-1] and diff[-2] < signal[-2]:
order_target_percent(context.s1, 1)
if diff[-1] < signal[-1] and diff[-2] > signal[-2]:
order_target_percent(context.s1, 0)
def after_trading(context):
pass
if __name__ == '__main__':
import rqalpha
rqalpha.run_func(init=init,
before_trading=before_trading,
handle_bar=handle_bar,
after_trading=after_trading,
config=__config__)
这个是根据大佬的代码抄的。其实数据还行,虽然没跑赢沪深三百,但是确实赚钱了,贴一下 源地址, 大佬说有一部分巧合在里面。不多说了。
我结合下只买五块钱的情况
#!/usr/bin/python3
# encoding: utf-8
# @Time : 2020/11/22 16:33
# @author : zza
# @Email : 740713651@qq.com
# @File : 闷声发小财。py
import numpy
import pandas
from rqalpha.apis import *
__config__ = {
"base": {
"start_date": "20190101",
"end_date": "20191231",
'frequency': '1d',
"accounts": {
"stock": 50000,
},
"data_bundle_path": r"E:\data\bundle",
},
"extra": {
"log_level": "debug",
},
"mod": {
"sys_progress": {
"enabled": True,
"show": True
}, "sys_accounts": {
"enabled": True,
"dividend_reinvestment": True,
},
"sys_analyser": {
"enabled": True,
"plot": True,
'benchmark': '000300.XSHG',
},
},
}
import talib
def init(context):
context.s1 = '000300.XSHG'
context.SHORTPERIOD = 12
context.LONGPERIOD = 26
context.SMOOTHPERIOD = 9
context.OBSERVATION = 100
subscribe(context.s1)
context.lowest = 5
context.highest = 6
context.order_ticker = []
def _history_bar_for_all_ins(x):
bar = history_bars(x, 1, "1d", fields=['close'])
if not bar:
return numpy.nan
if bar[0]:
return bar[0][0]
return numpy.nan
def get_ticker(context):
all_ins = all_instruments("Stock").order_book_id.to_list()
df = pandas.DataFrame(all_ins, columns=['order_book_id'])
df['close'] = df.order_book_id.apply(_history_bar_for_all_ins)
price_df = df[(context.lowest <= df.close) & (df.close <= context.highest)]
order_ticker = []
for order_book_id in price_df.order_book_id.to_list():
c = pandas.Series(i[0] for i in history_bars(order_book_id, 3, "1d", fields=['close']))
if (c.shift(fill_value=0) < c).all():
order_ticker.append(order_book_id)
return order_ticker
def before_trading(context):
print("年化:{}".format(context.portfolio.total_returns))
def handle_bar(context, bar_dict):
closes = history_bars(context.s1, context.OBSERVATION, '1d', 'close')
diff, signal, _ = talib.MACD(closes)
if diff[-1] > signal[-1] and diff[-2] < signal[-2] :
if context.stock_account.cash > 1000:
context.order_ticker = get_ticker(context)
for item in context.order_ticker:
o = order_target_value(item, 2000)
if o:
print(o)
print("context.order_ticker", context.order_ticker)
if diff[-1] < signal[-1] and diff[-2] > signal[-2]:
for item in context.portfolio.positions.keys():
order_target_percent(item, 0)
def after_trading(context):
context.order_ticker = []
if __name__ == '__main__':
import rqalpha
rqalpha.run_func(init=init,
before_trading=before_trading,
handle_bar=handle_bar,
after_trading=after_trading,
config=__config__)
还不如直接买华夏国运沪深三百。

试试朋友的想法
假如设置一个均值(��一直在变),低于 0.8 倍均值(mean_coe),并且连续 fall_days 天,跌幅加起来达到 fall_x%,买入 高于买入价格,并且连续 rise_days 天,涨幅加起来达到 rise_x%,卖出
我开始简单的设置了几个参数,发现结果不是很理想,但是没亏,我就想可能是参数的问题,然后列出了个集合,想着再跑跑,代码如下:
#!/usr/bin/python3
# encoding: utf-8
# @Time : 2020/11/22 16:33
# @author : zza
# @Email : 740713651@qq.com
import itertools
import numpy
import pandas
from rqalpha.apis import *
__config__ = {
"base": {
"start_date": "20190101",
"end_date": "20191231",
'frequency': '1d',
"accounts": {
"stock": 50000,
},
"data_bundle_path": r"E:\data\bundle",
},
"extra": {
"log_level": "debug",
},
"mod": {
"sys_progress": {
"enabled": True,
"show": True
}, "sys_accounts": {
"enabled": True,
"dividend_reinvestment": True,
},
"sys_analyser": {
"enabled": True,
"plot": True,
'benchmark': '000300.XSHG',
},
},
}
def init(context):
context.mean_coe = 0.8
context.mean_days = 244
context.rise_days = context.config.extra.rise_days
context.fall_days = context.config.extra.fall_days
context.rise_x = context.config.extra.rise_x
context.fall_x = context.config.extra.fall_x
context.order_ticker = [
"002111.XSHE", # 威海广泰
"002673.XSHE", # 西部证券
"601375.XSHG", # 中原证券
]
df = all_instruments('CS')
df = df[df.listed_date.apply(lambda x: x.year in [2015, 2016, 2017])]
context.order_ticker = context.order_ticker + df.order_book_id.to_list()
def before_trading(context):
print("年化:{}".format(context.portfolio.total_returns))
# 价格均值
context.mean_close = {}
for order_book_id in context.order_ticker:
bars = pandas.Series([i[0] for i in history_bars(order_book_id, context.mean_days, "1d", fields=['close'])])
context.mean_close[order_book_id] = bars.mean()
def handle_bar(context, bar_dict):
# for buy
if context.stock_account.cash >= 5000:
for order_book_id in context.order_ticker:
bar_close = bar_dict[order_book_id].close
if bar_close < (context.mean_close[order_book_id] * context.mean_coe):
_str = ""
bars = pandas.Series(
[i[0] for i in history_bars(order_book_id, context.fall_days, "1d", fields=['close'])])
_str += "\n" + f"[{order_book_id}] 价格 ({bar_close}) �低于一年平均价{context.mean_close[order_book_id]}"
if not (bars.shift(-1, fill_value=0) < bars).all():
# 判断连跌
continue
_str += "\n" + f"[{order_book_id}] 连跌 价格表现为{list(bars)}"
if not (bars[0] * context.fall_x > bar_close):
# 判断跌幅
# 非低于 0.8 倍均值(mean_coe)
continue
_str += "\n" + f"[{order_book_id}] 跌幅超过{context.fall_x}, {bars[0]} - {bar_close}"
o = order_value(order_book_id, 5000)
if o:
_str += "\n" + f"[{order_book_id}] 买入".format(order_book_id)
print(_str)
# for sell
for order_book_id in context.order_ticker:
position = context.portfolio.positions[order_book_id]
bar_close = bar_dict[order_book_id].close
if position is None or position.quantity <= 0:
continue
if position.avg_price < bar_close:
# 低于买入价格 不做操作
continue
_str = ""
bars = pandas.Series([i[0] for i in history_bars(order_book_id, context.fall_days, "1d", fields=['close'])])
if not (bars.shift(1, fill_value=0) < bars).all():
# 并且连续 rise_days 天
continue
_str += "\n" + f"[{order_book_id}] 连涨 价格表现为{list(bars)}"
if not (bars[0] * context.rise_x < bar_close):
# 涨幅加起来达到 rise_x%
continue
_str += "\n" + f"[{order_book_id}] 涨幅超过{context.rise_x}, {bars[0]} - {bar_close}"
o = order_target_percent(order_book_id, 0)
if o:
_str += "\n" + f"[{order_book_id}] 出售".format(order_book_id)
print(_str)
def after_trading(context):
pass
import rqalpha
rise_days = range(3, 10)
fall_days = range(3, 10)
rise_x = numpy.arange(1.06, 1.12, 0.01)
fall_x = numpy.arange(0.9, 0.94, 0.01)
config_map = itertools.product(rise_days, fall_days, rise_x, fall_x)
df = pandas.DataFrame(config_map, columns=["rise_days", "fall_days", "rise_x", "fall_x", ])
result_list = []
for _, item in df.iterrows():
__config__['extra']['rise_days'] = int(item.rise_days)
__config__['extra']['fall_days'] = int(item.fall_days)
__config__['extra']['rise_x'] = item.rise_x
__config__['extra']['fall_x'] = item.fall_x
result = rqalpha.run_func(init=init,
before_trading=before_trading,
handle_bar=handle_bar,
after_trading=after_trading,
config=__config__)
total_returns = result['sys_analyser']['summary']['total_value']
result_list.append(result)
其实跑出了几个超过大盘收益的结果。但是因为我的代码水平问题,报错了,结果也没保存,近期我会去吧这个跑完(1300 多的组合方式),有结果了我会贴上最优解的。
我还是不在股票市场里当韭菜了 溜了溜了

20200413 一面:
二面:
三面:
反问:
HR:
2021-09-02 QQ音乐
class Person:
name="aaa"
p1=Person()
p2=Person()
p1.name="bbb"
print(p1.name) # bbb
print(p2.name) # aaa
print(Person.name) # aaa
简单一句就是运行时能够获得对象的类型.比如type(),dir(),getattr(),hasattr(),isinstance().
foo:一种约定,Python内部的名字,用来区别其他用户自定义的命名,以防冲突,就是例如__init__(),del(),call()这些特殊方法
_foo:一种约定,用来指定变量私有.程序员用来指定私有变量的一种方式.不能用from module import * 导入,其他方面和公有一样访问;
__foo:这个有真正的意义:解析器用_classname__foo来代替这个名字,以区别和其他类相同的命名,它无法直接像公有成员一样随便访问,通过对象名._类名__xxx这样的方式可以访问.
问: 将列表生成式中[]改成() 之后数据结构是否改变?
答案:是,从列表变为生成器
迭代器:迭代器是一个可以记住遍历的位置的对象:next(iter([1,2,3,4]))
class MyNumbers:
def __iter__(self):
self.a = 1
return self
def __next__(self):
x = self.a
self.a += 1
if self.a> 3:
raise StopIteration
return x
myclass = MyNumbers()
myiter = iter(myclass)
print(next(myiter))
print(next(myiter))
生成器:使用了 yield 的函数被称为生成器(generator),简单点理解生成器就是一个迭代器。
被用于有切面需求的场景:插入日志、性能测试、事务处理等。
装饰器的作用就是为已经存在的对象添加额外的功能。
函数重载主要是为了解决两个问题。
可变参数类型。
可变参数个数。
Python 都不需要
python的多父类继承问题
新式类继承是根据C3算法,旧式类是深度优先。
在Python3.6下,className.mro()查看继承顺序。
__slots__是一个类变量,__slots__属性可以赋值一个包含类属性名的字符串元组, 或者是可迭代变量,或者是一个字符串,只要在类定义的时候, 使用__slots__ = a Tuple来定义该属性就可以了。
这个__new__确实很少见到,先做了解吧.
__new__是一个静态方法,而__init__是一个实例方法.
__new__方法会返回一个创建的实例,而__init__什么都不返回.
只有在__new__返回一个cls的实例时后面的__init__才能被调用.
当创建一个新实例时调用__new__,初始化一个实例时用__init__.
ps: __metaclass__是创建类时起作用.所以我们可以分别使用__metaclass__,__new__和__init__来分别在类创建,实例创建和实例初始化的时候做一些小手脚.
class Singleton(object):
def __new__(cls, *args, **kw):
if not hasattr(cls, '_instance'):
orig = super(Singleton, cls)
cls._instance = orig.__new__(cls, *args, **kw)
return cls._instance
class MyClass(Singleton):
a = 1
# --------------------
# 装饰器版本
def singleton(cls):
instances = {}
def getinstance(*args, **kw):
if cls not in instances:
instances[cls] = cls(*args, **kw)
return instances[cls]
return getinstance
@singleton
class MyClass:
...
# --------------------
# 作为python的模块是天然的单例模式
# mysingleton.py
class My_Singleton(object):
def foo(self):
pass
my_singleton = My_Singleton()
# to use
from mysingleton import my_singleton
my_singleton.foo()
class Borg(object):
_state = {}
def __new__(cls, *args, **kw):
ob = super(Borg, cls).__new__(cls, *args, **kw)
ob.__dict__ = cls._state
return ob
class MyClass2(Borg):
a = 1
Python 中,一个变量的作用域总是由在代码中被赋值的地方所决定的。
当 Python 遇到一个变量的话他会按照这样的顺序进行搜索:
本地作用域(Local)→当前作用域被嵌入的本地作用域(Enclosing locals)→全局/模块作用域(Global)→内置作用域(Built-in)
线程全局锁(Global Interpreter Lock),即Python为了保证线程安全而采取的独立线程运行的限制, 说白了就是一个核只能在同一时间运行一个线程. 对于io密集型任务,python的多线程起到作用, 但对于cpu密集型任务,python的多线程几乎占不到任何优势,还有可能因为争夺资源而变慢。
在python3.x中,GIL不使用ticks计数, 改为使用计时器(执行时间达到阈值后,当前线程释放GIL), 这样对CPU密集型程序更加友好, 但依然没有解决GIL导致的同一时间只能执行一个线程的问题
闭包可以保存当前的运行环境 闭包必须满足以下几点:
>>>a = [1,2,3,4,5,6,7]
>>>b = filter(lambda x: x > 5, a)
>>>print b
>>>[6,7]
>>> a = map(lambda x:x*2,[1,2,3])
>>> list(a)
[2, 4, 6]
from functools import reduce
...: def c(x,y):
...: print(x,y)
...: return x*y
...: reduce(c,range(1,5))
1 2
2 3
6 4
Out[10]: 24
Python GC主要使用引用计数(reference counting)来跟踪和回收垃圾。 当一个对象有新的引用时,它的ob_refcnt就会增加, 当引用它的对象被删除,它的ob_refcnt就会减少. 引用计数为0时,该对象生命就结束了。
基本思路是先按需分配,等到没有空闲内存的时候从寄存器和程序栈上的引用出发, 遍历以对象为节点、以引用为边构成的图,把所有可以访问到的对象打上标记, 然后清扫一遍内存空间,把所有没标记的对象释放。
Python默认定义了三代对象集合,索引数越大,对象存活时间越长。
当某些内存块M经过了3次垃圾收集的清洗之后还存活时, 我们就将内存块M划到一个集合A中去,而新分配的内存都划分到集合B中去。 当垃圾收集开始工作时,大多数情况都只对集合B进行垃圾回收。
select有3个缺点:
poll使用pollfd结构而不是select的fd_set结构,poll改善了第一个缺点。
epoll改了三个缺点. poll在“醒着”的时候只要判断一下就绪链表是否为空就行了
高级调度(作业调度/长程调度)(频率低):将外存作业调入内存
低级调度(进程调度/短程调度)(频率高):决定就就绪队列中哪个进程获得处理机并执行
什么是调度?本质上就是一种资源分配
什么是饥饿?某写进程一直在等待,得不到处理
调度算法的分类
- 抢占式(当前进程可以被抢):可以暂停某个正在执行的进程,将处理及重新分配给其他进程
- 非抢占式(当前进程不能被抢走):一旦处理及分配给了某个进程,他就一直运行下去,直到结束
具体调度算法:
- 1.先来先服务(FCFS):按照到达顺序,非抢占式,不会饥饿
- 2.短作业/进程优先(SJF):抢占/非抢占,会饥饿
- 3.高响应比优先(HRRN):综合考虑等待时间和要求服务事件计算一个优先权,非抢占,不会饥饿
- 4.时间片轮转(RR):轮流为每个进程服务,抢占式,不会饥饿
- 5.优先级:根据优先级,抢占/非抢占,会饥饿
- 6.多级反馈队列:
- 设置多个就绪队列,每个队列的进程按照先来先服务排队,然后按照时间片轮转分配时间片
- 若时间片用完还没有完成,则进入下一级队尾,只有当前队列为空时,才会为下一级队列分配时间片。
- 抢占式,可能会饥饿
作业调度算法:
- 先来先服务调度算法
- 短作业优先调度算法
- 优先级调度算法
进程调度算法:
- 以上6种都可以是进程调度算法
原因:
必要条件:
处理死锁基本方法:
边缘触发是指每当状态变化时发生一个 io 事件,条件触发是只要满足条件就发生一个 io 事件
yeild async await Generator 是一个异步实现的生成器 ,是协程 。 协程是用户态的线程。
装饰器的本质是一个闭包函数,而闭包函数的本质是变量作用域的外溢。 (外层函数中包裹的内部函数可使用外层函数的参数,以及接受其值)
sudo lsof -i:端口号 //查找对应的进程号
sudo kill -9 进程号 //杀死对应的进程
find -size +10k -15k
grep -rn "phpernote" * -C 5
-r 是递归查找 -n 是显示行号 -C number 匹配的上下文分别显示[number]行
Linux 上的命名空间(Namespaces)、 控制组(Control groups)、 Union 文件系统(Union file systems) 和容器格式(Container format)。
堆栈FILO 队列FIFO
可以使用redis的定时存储key-value方式 EXPIRE key timeout, 获取key时没有这个key,则认为订单失效,让当前程序拿取订单信息,返回用户提示订单失败。
聚集索引,非聚集索引,B-Tree,B+Tree
Redis是一个完全开源免费的key-value内存数据库,通常被认为是一个数据结构服务器,主要是因为其有着丰富的数据结构 strings、map、 list、sets、 sorted sets
缺点:
MyISAM 适合于一些需要大量查询的应用,但其对于有大量写操作并不是很好。 甚至你只是需要update一个字段,整个表都会被锁起来,而别的进程,就算是读进程都无法操作直到读操作完成。 另外,MyISAM 对于 SELECT COUNT(*) 这类的计算是超快无比的。
InnoDB 的趋势会是一个非常复杂的存储引擎,对于一些小的应用,它会比 MyISAM 还慢。 他是它支持“行锁” ,于是在写操作比较多的时候,会更优秀。并且,他还支持更多的高级应用,比如:事务。
注意: 中断连接端可以是客户端,也可以是服务器端. 下面仅以客户端断开连接举例, 反之亦然.
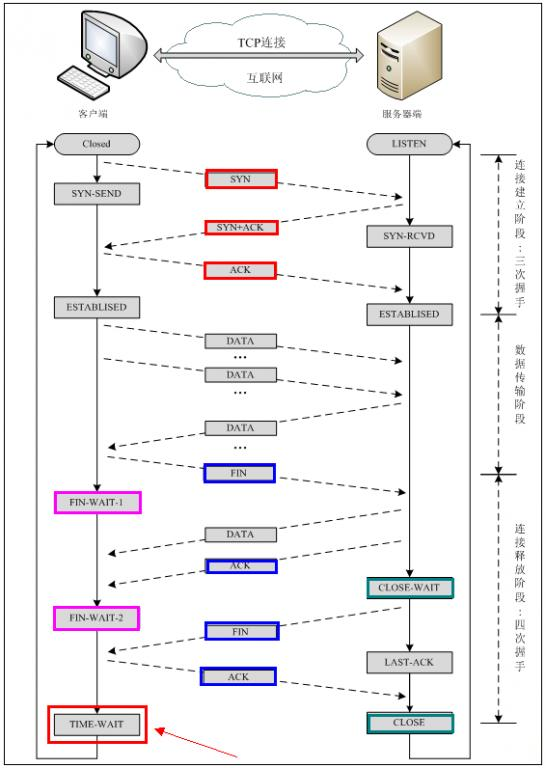
HTTP方法的幂等性是指一次和多次请求某一个资源应该具有同样的副作用。(注意是副作用)
GET的URL会被放在浏览器历史和WEB 服务器日志里面。,POST 发完基本就没有了。post可以发送的数据够大,get受某些版本ie限制发不了多少东西。get会被认为是幂等的,也就是请求1次和n次是一样的。
nginx 相对 apache 的��优点:
apache 相对nginx 的优点:
APISIX: 和传统 API 网关相比, 具备动态路由和插件热加载,特别适合微服务体系下的 API 管理。
CSRF重点在请求,XSS重点在脚本
CGI是通用网关接口,是连接web服务器和应用程序的接口,用户通过CGI来获取动态数据或文件等。 CGI程序是一个独立的程序,它可以用几乎所有语言来写,包括perl,c,lua,python等等。
WSGI, Web Server Gateway Interface,是Python应用程序或框架和Web服务器之间的一种接口,WSGI的其中一个目的就是让用户可以用统一的语言(Python)编写前后端。
Socket=Ip address+ TCP/UDP + port
Cache-control:值可以是public、private、no-cache、no- store、no-transform、must-revalidate、proxy-revalidate、max-age no-cache代表不缓存过期的资源,缓存会向服务器进行有效处理确认之后处理资源 而no-store才是真正的不进行缓存。 304 Not Modified
AJAX,Asynchronous JavaScript and XML(异步的 JavaScript 和 XML), 是与在不重新加载整个页面的情况下,与服务器交换数据并更新部分网页的技术。
from multiprocessing import Process, Pipe
Pipe().send("Hello 11")
import os
fd = os.open('pipetest',os.O_NONBLOCK | os.O_CREAT | os.O_RDWR)
os.write(fd,"hello")
import signal
signal.signal(signal.SIGTERM,lambda a,b;print(a,b))
import Queue
Queue.Queue().put
import mmap
with contextlib.closing(mmap.mmap(-1, 100, tagname='SASU', access=mmap.ACCESS_WRITE)) as m:
m.write()
m.flush()
原理:给定一个数量,对多个进程可见,且多个进程都可以操作。进程通过对数量多少的判断执行各自的行为。(生产者/消费者)
multiprocessing --> Semaphore()
sem = Semaphore(num)
功能:创建信号量
参数:信号量初始值
返回:信号量对象
sem.get_value() 获取信号量值
sem.acquire() 将信号量减1 当信号量为0时会阻塞
sem.release() 将信号量加1
import socket
HTTP在应用层,TCP 和 UDP 都位于计算机网络模型中的运输层。 HTTP 中包括许多方法,Get ,Post 等。
看循环嵌套 增长方式 循环结束条件
# log2 N
for(i=0;i<n:i*2)
a++
MySQL 之所以选择 B+,那是因为出于范围选择��考虑的。那么 MongoDB 选择 B 树,可能是因为单一数据查询多,范围查询少。
| 名称 | 应用场景方面 | 架构模型方面 | 吞吐量方面 | 集群负载均衡方面 |
|---|---|---|---|---|
| RabbitMQ | 用于实时的,对可靠性要求较高的消息传递上。 | 以broker为中心,有消息的确认机制。 | 支持消息的可靠的传递,支持事务,不支持批量操作,基于存储的可靠性的要求存储可以采用内存或硬盘,吞吐量小。 | 本身不支持负载均衡,需要loadbalancer的支持 |
| kafka | 用于处于活跃的流式数据,大数据量的数据处理上。 | 以consumer为中心,无消息的确认机制。 | 内部采用消息的批量处理,数据的存储和获取是本地磁盘顺序批量操作,消息处理的效率高,吞吐量高。 | 采用zookeeper对集群中的broker,consumer进行管理,可以注册topic到zookeeper上,通过zookeeper的协调机制,producer保存对应的topic的broker信息,可以随机或者轮询发送到broker上,producer可以基于语义指定分片,消息发送到broker的某个分片上。 |
我拿普罗米斯的日志看的
GET请求的 总请求数量 / 总等待时长 = QPS
668971.0 / 7273.539398193359 = 91.97324
大概92,也不知道时多时少
因为不是纯GET请求,也算数据库写入,所以我觉得也算TPS。
简单版本
这道题拓展性极高: https://www.zhihu.com/question/437193010/answer/1653724247
因为放在Todo list有多端同步问题,数据会消失,所以换成简书记录。
待整理资料
https://github.com/resumejob/interview-questions https://github.com/hantmac/Python-Interview-Customs-Collection https://github.com/jackfrued/Python-Interview-Bible/blob/master/Python%E9%9D%A2%E8%AF%95%E5%AE%9D%E5%85%B8-%E5%9F%BA%E7%A1%80%E7%AF%87-2020.md https://github.com/resumejob/interview-questions#%E8%85%BE%E8%AE%AF https://github.com/julycoding/The-Art-Of-Programming-By-July/blob/master/ebook/zh/03.01.md https://www.cnblogs.com/Leo_wl/p/12076011.html
https://mp.weixin.qq.com/s/ENWm8W2hBvlw5pBDQTHpfA https://my.oschina.net/yzbty32/blog/549305 https://juejin.cn/post/6844903958624878606
https://github.com/taizilongxu/interview_python https://zhuanlan.zhihu.com/p/20953544 https://www.jianshu.com/p/2a17957ce https://www.jianshu.com/p/J4U6rR https://www.runoob.com/python3/python3-namespace-scope.html https://zhuanlan.zhihu.com/p/73204847 https://xieguanglei.github.io/blog/post/red-black-tree.html https://www.jianshu.com/p/c25601f0cc43 https://blog.csdn.net/u013129109/article/details/79608384 https://www.cnblogs.com/nankezhishi/archive/2012/06/09/getandpost.html https://www.cnblogs.com/0201zcr/p/5296843.html https://segmentfault.com/a/1190000008227211 https://zhuanlan.zhihu.com/p/34248254